Recent Interesting News
Llama 3.2 Family is released.
Chain of Thought(CoT)
Survey
- Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs by Y. Xia et al.
Different Approaches of CoX, for example,
- Chain-of-Thought
- Chain-of-Augmentation: Add external information into each step
- Chain-of-Feedback: Provide human feedback into each step
- Chain-of-Models: Implement different steps by different LLMs (Agents)
Paper
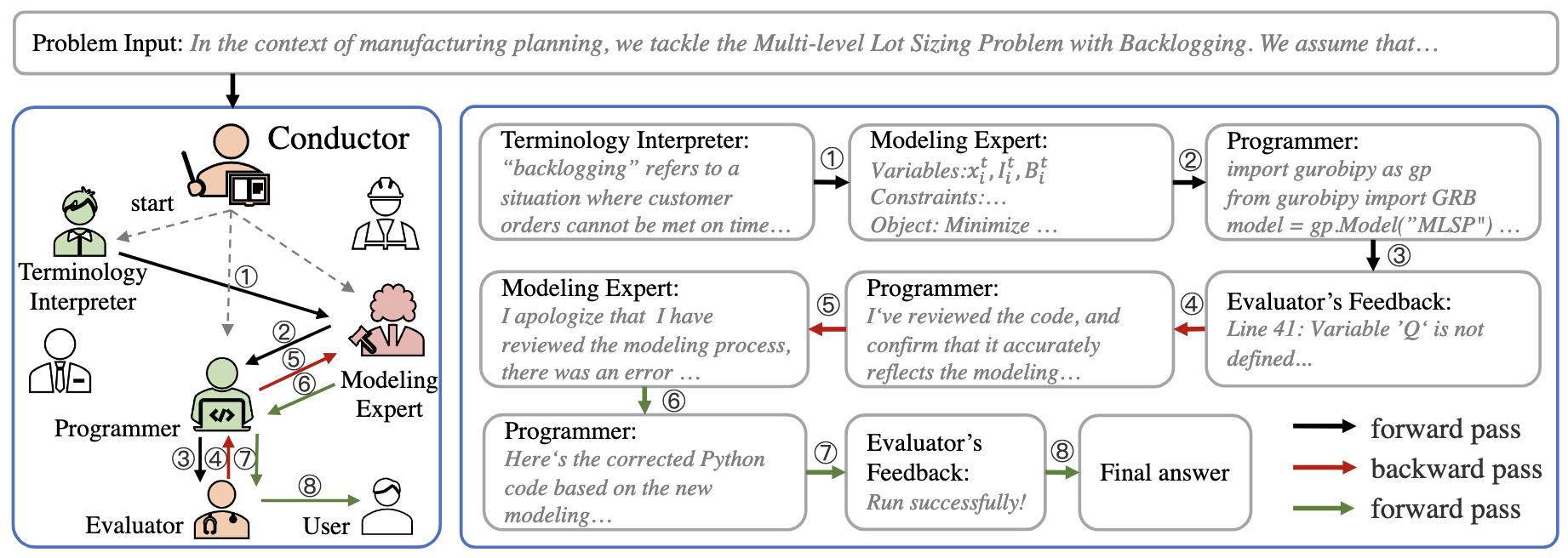
CHAIN-OF-EXPERTS: WHEN LLMS MEET COMPLEX OPERATIONS RESEARCH PROBLEMS by Z. Xiao et al.
Type: Chain-of-Models
Involved multiple LLMs or so-called agents to implement different steps of thought
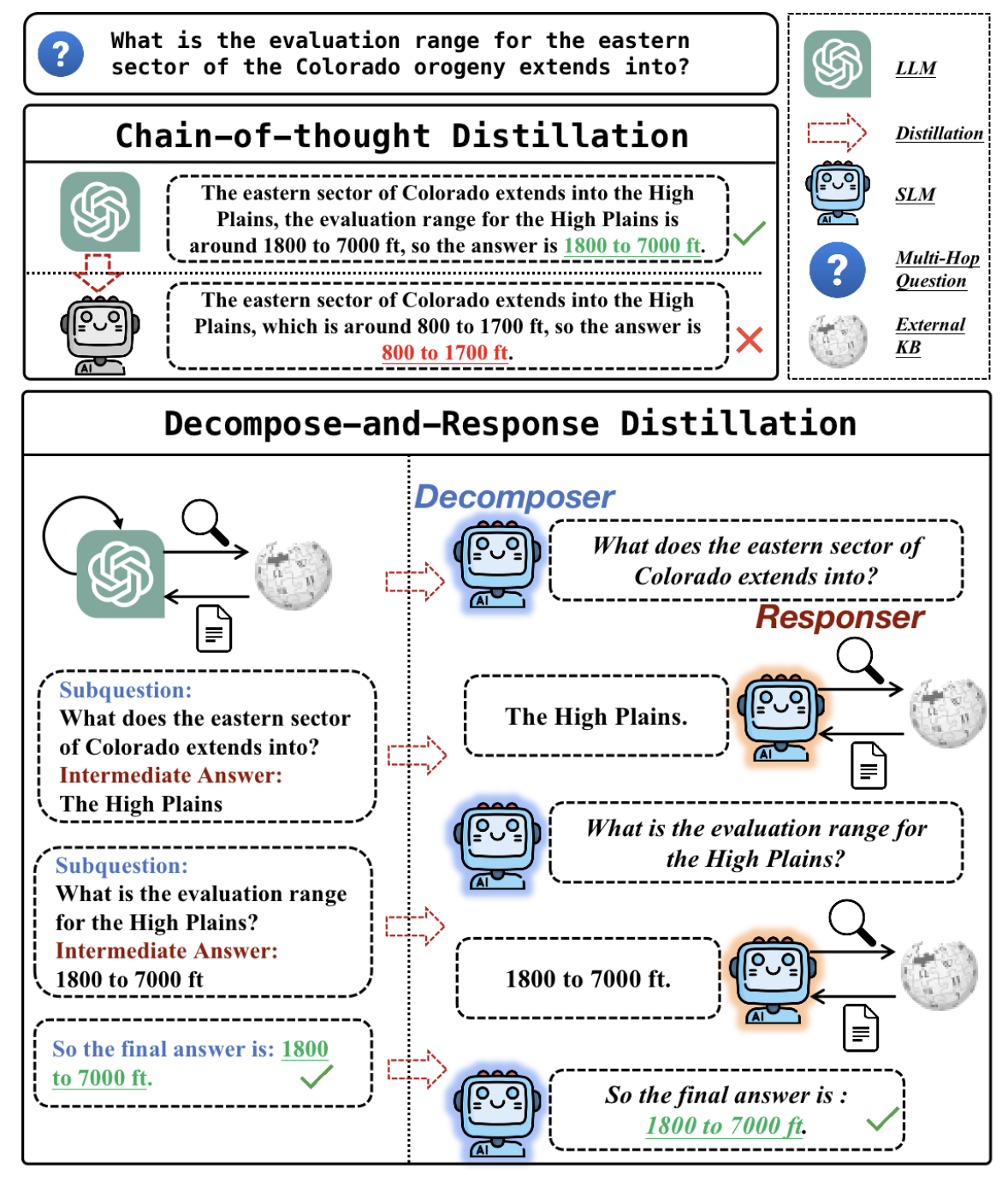
Teaching Small Language Models to Reason for Knowledge-Intensive Multi-Hop Question Answering by X. Li et al.
Distillation by generating sub-questions from LLMs to train SLMs with CoT, called Decompose and Response Distillation
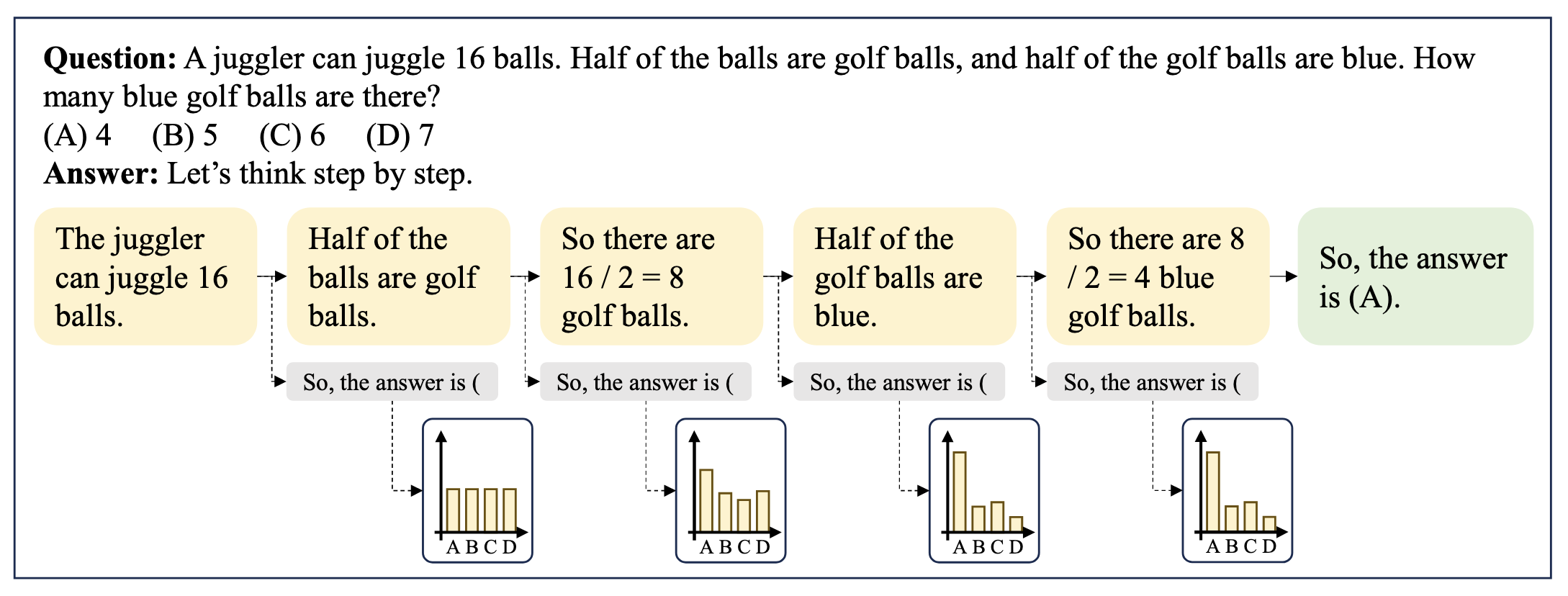
Chain-of-Probe: Examing the Necessity and Accuracy of CoT Step-by-Step by Z. Wang et al.
Early Answering :
LLMs have already predicted an answer before generating the CoT.
Teaching Small Language Models to Reason by L. C. Magister, J. Mallinson, J. Adamek, E. Malmi, and A. Severyn
Large Language Models Are Reasoning Teachers by N. Ho, L. Schmid, and S.-Y. Yun
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning by Z. Sprague et al.
On-device and Edge-cloud collaboration of LLM/Small
Survey
- On-Device Language Models: A Comprehensive Review by J. Xu et al.
- What is the Role of Small Models in the LLM Era: A Survey by L. Chen and G. Varoquaux