Intro
The goal in this paper is to advance methods for training language models on objectives that more closely capture the behavior we care about. To make short-term progress towards this goal, we focus on abstractive English text summarization, as it has a long history in the NLP community, and is a subjective task where we believe it is difficult to quantify summary quality without human judgments. Indeed, existing automatic metrics for evaluating summary quality, such as ROUGE, have received criticism for poor correlation with human judgments.
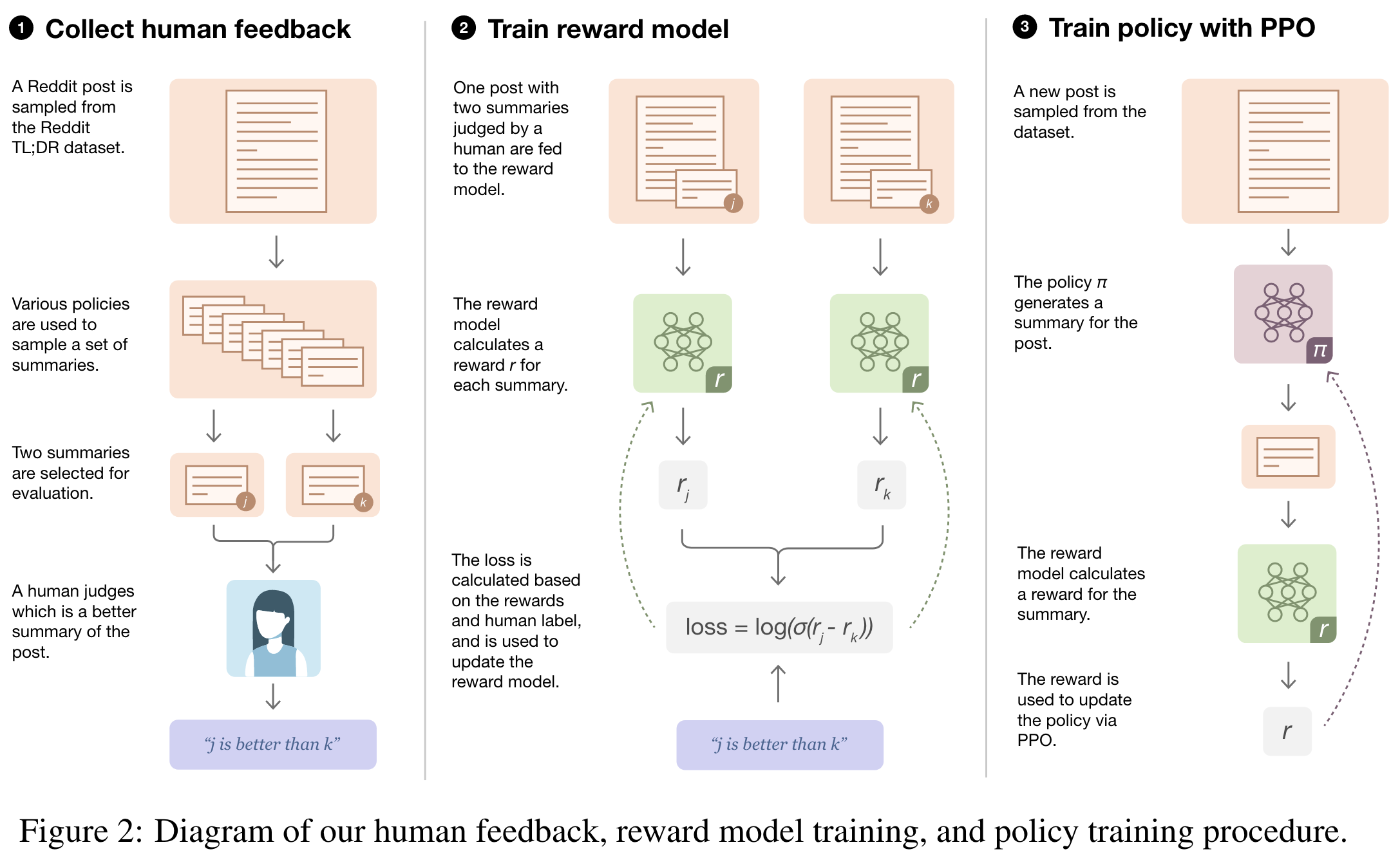
- collect a dataset of human preferences between pairs of summaries
- train a reward model (RM) via supervised learning to predict the human-preferred summary
- we train a policy via reinforcement learning (RL) to maximize the score given by the RM; the policy generates a token of text at each ‘time step’, and is updated using the PPO algorithm based on the RM ‘reward’ given to the entire generated summary.
Method
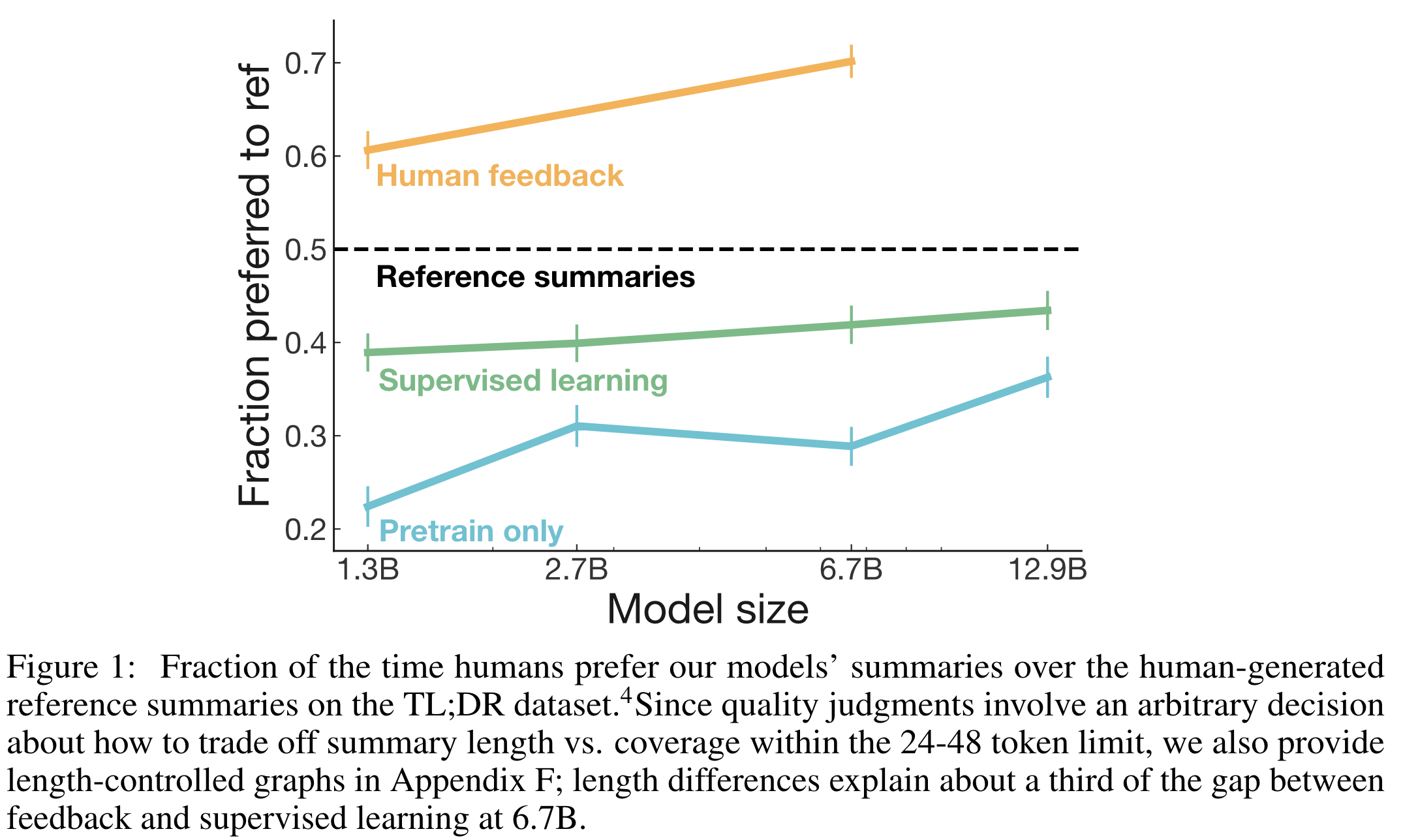
- training with human feedback significantly outperforms very strong baselines on English summarization
- human feedback models generalize much better to new domains than supervised models
- extensive empirical analyses of policy and reward model
Result