Motivation
GPU is the dominant resource for DNN training
Existing schedulers consider GPU as the dominant resource and allocate other resources such as CPU and memory proportional to the number of GPUs requested by the job (GPU-proportional allocation).
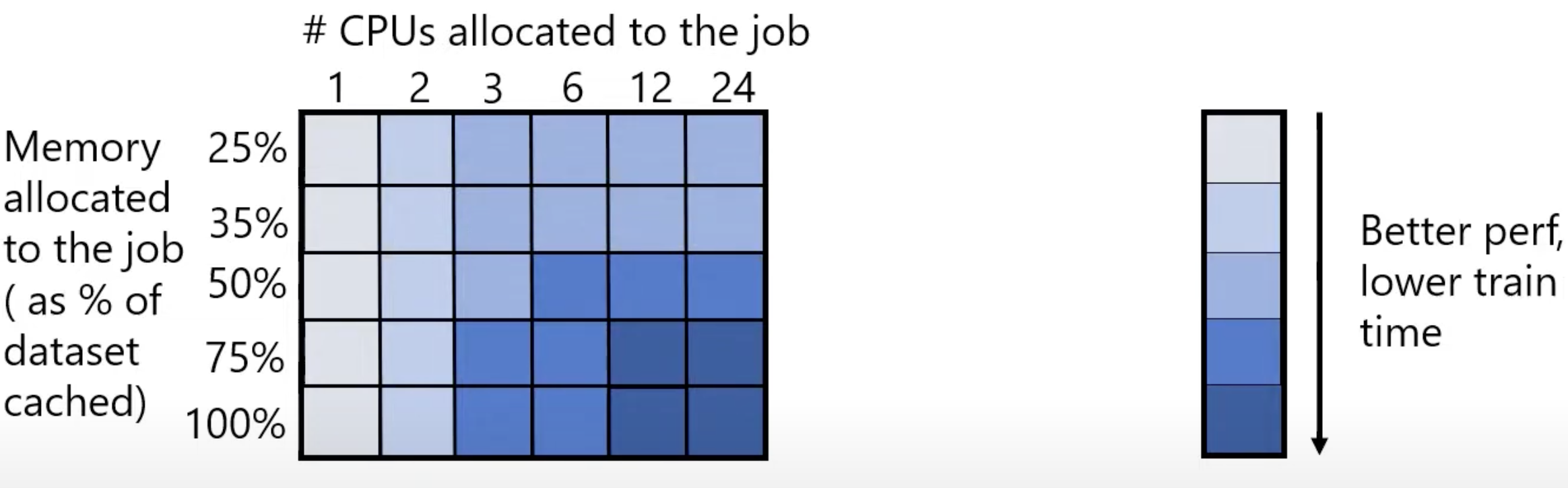
CPU and memory are also important for DNN training for some specific applecation, and different DNNs exhibit different levels of sensitivity to CPU and memory allocations.
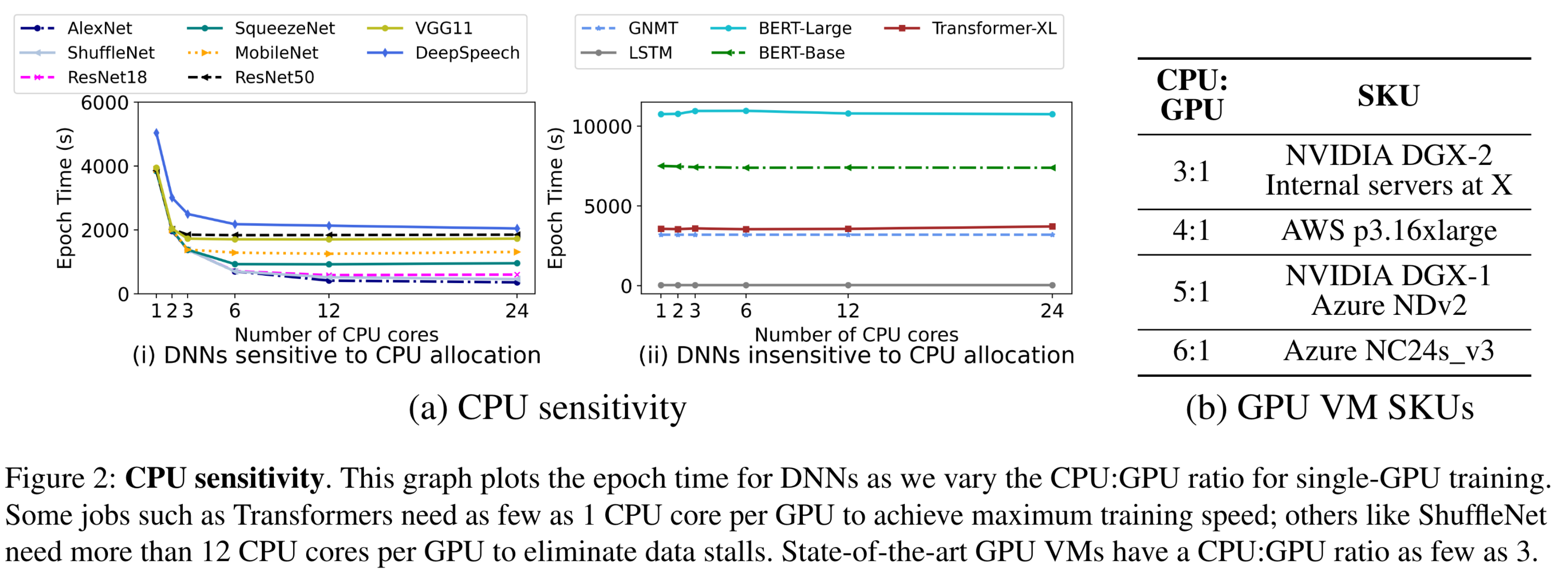
- image and video recognition models achieve up to 3× speedup when the CPUs allocated exceed their GPU-proportional share.
- some models like
GNMTare not affected by less than GPU-proportional allocation.
This is because they have modest input data pre-processing requirements. Transformer models for example, unlike image classification models, do not perform several unique data augmentation operations for each data item in every epoch
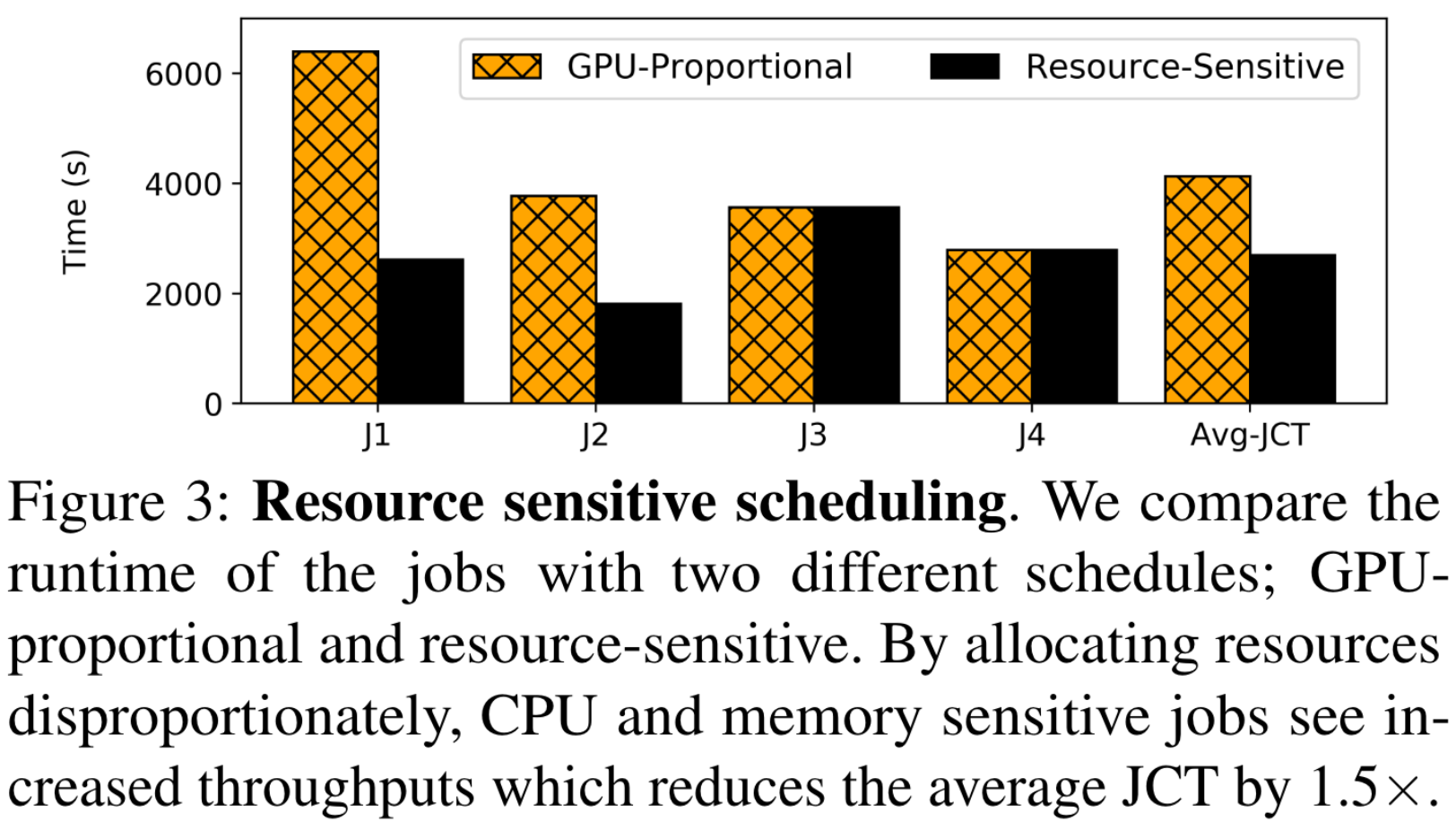
Exploit the disparity in resource requirements across jobs to improve overall cluster utilization without any hardware upgrades (storage, CPU, or memory).
GNMT is insensitive to memory allocation; even if only 20GB memory is allocated (which is the required process memory for training), the training throughput is unaffected. However, increasing the memory from 62GB (GPUproportional allocation) to 500GB (max) for ResNet18 speeds up training by almost 2×.
This is because, language models like GNMT, and transformers are GPU compute bound. Therefore, fetching data items from storage if they are not available in memory does not affect training throughput.
On the other hand, image and speech models benefit from larger DRAM caches. If a data item is not cached, the cost of fetching it from the storage device can introduce fetch stalls in training.
When two jobs have to be scheduled on the same server, it is possible to co-locate a CPU-sensitive job with a CPU-insensitive one or a memory-sensitive job with an insensitive one.

Design
Synergy is a round-based scheduler that arbitrates multi-dimensional resources (GPU, CPU, and memory) in a homogeneous cluster.
- First, it identifies the job’s best-case CPU and memory requirements using optimistic profiling.
- Synergy then identifies a set of runnable jobs for the given round using a scheduling policy (e.g., SRTF, FTF, LAS, etc) such that their collective GPU demand is less than or equal to the GPUs available in the cluster.
- Then, using the profiled resource demands, Synergy packs these jobs on to the available servers along multiple resource dimensions using a near-optimal heuristic algorithm
- At the end of a round, the set of runnable jobs are updated using the scheduling policy, and their placement decisions are recomputed.
Optimistic Profiling
A DNN job is profiled for its resource sensitivity once per lifetime of the job, i.e. on job arrival. Since DNN training has a highly predictable structure, empirically evaluating training throughput for a few iterations gives a fair estimate of the actual job throughput.
Why optimistic profiling?
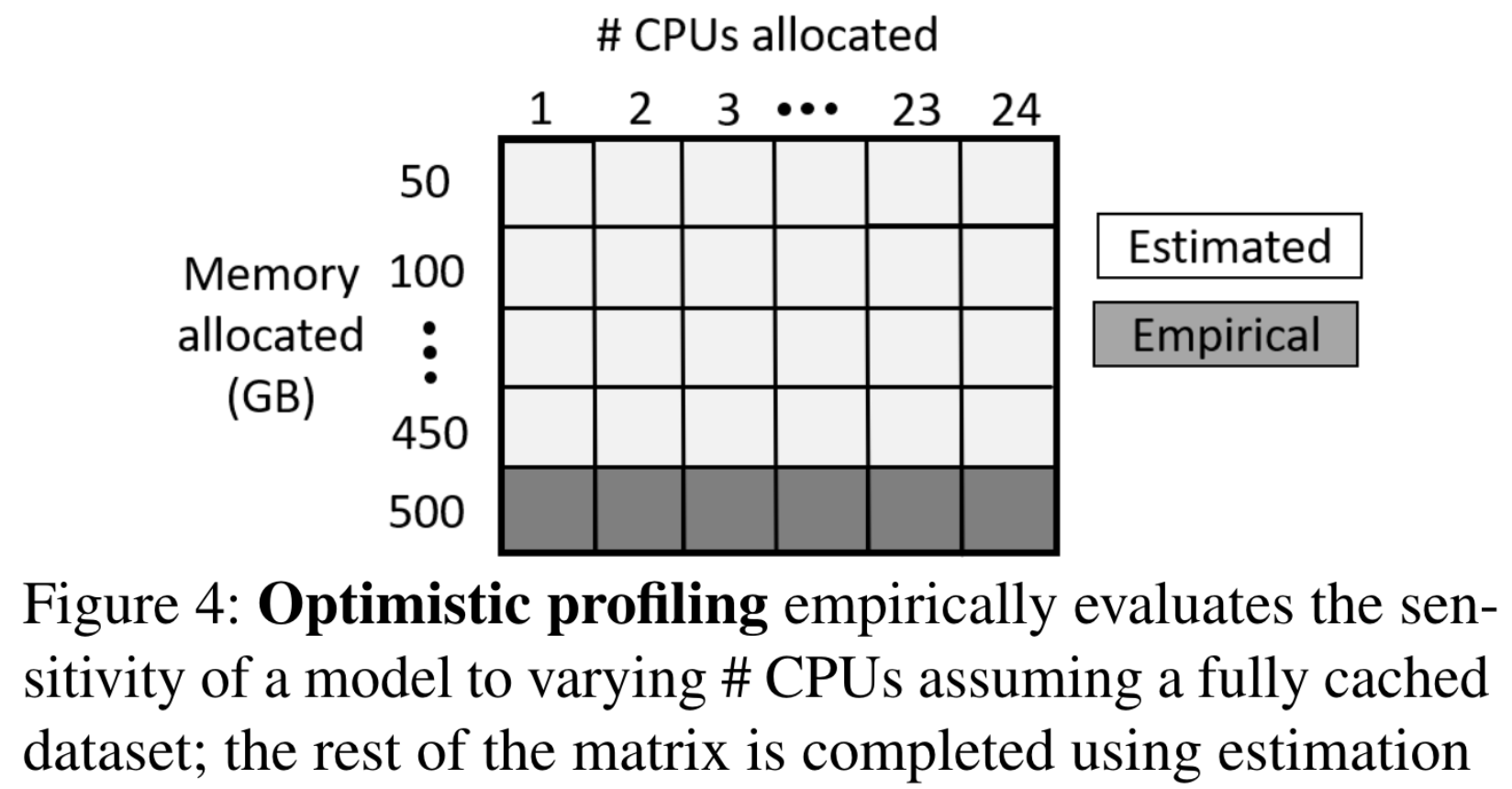 Because the # of combinations of CPU and memory is too large, it is infeasible to profile all combinations. If the cost of profiling one combination of CPU, and memory for a job is 1 minute, then to profile all discrete combinations of CPU and memory (assuming allocation in units of 50GB) on a server with 24 CPUs and 500GB DRAM takes about 24*10 = 240 minutes (4 hours)
Because the # of combinations of CPU and memory is too large, it is infeasible to profile all combinations. If the cost of profiling one combination of CPU, and memory for a job is 1 minute, then to profile all discrete combinations of CPU and memory (assuming allocation in units of 50GB) on a server with 24 CPUs and 500GB DRAM takes about 24*10 = 240 minutes (4 hours)
It is easy to model the job throughput behaviour as we vary the amount of memory allocated to a job at fixed CPU allocation with DNN-specific, application-level caches like MinIO.
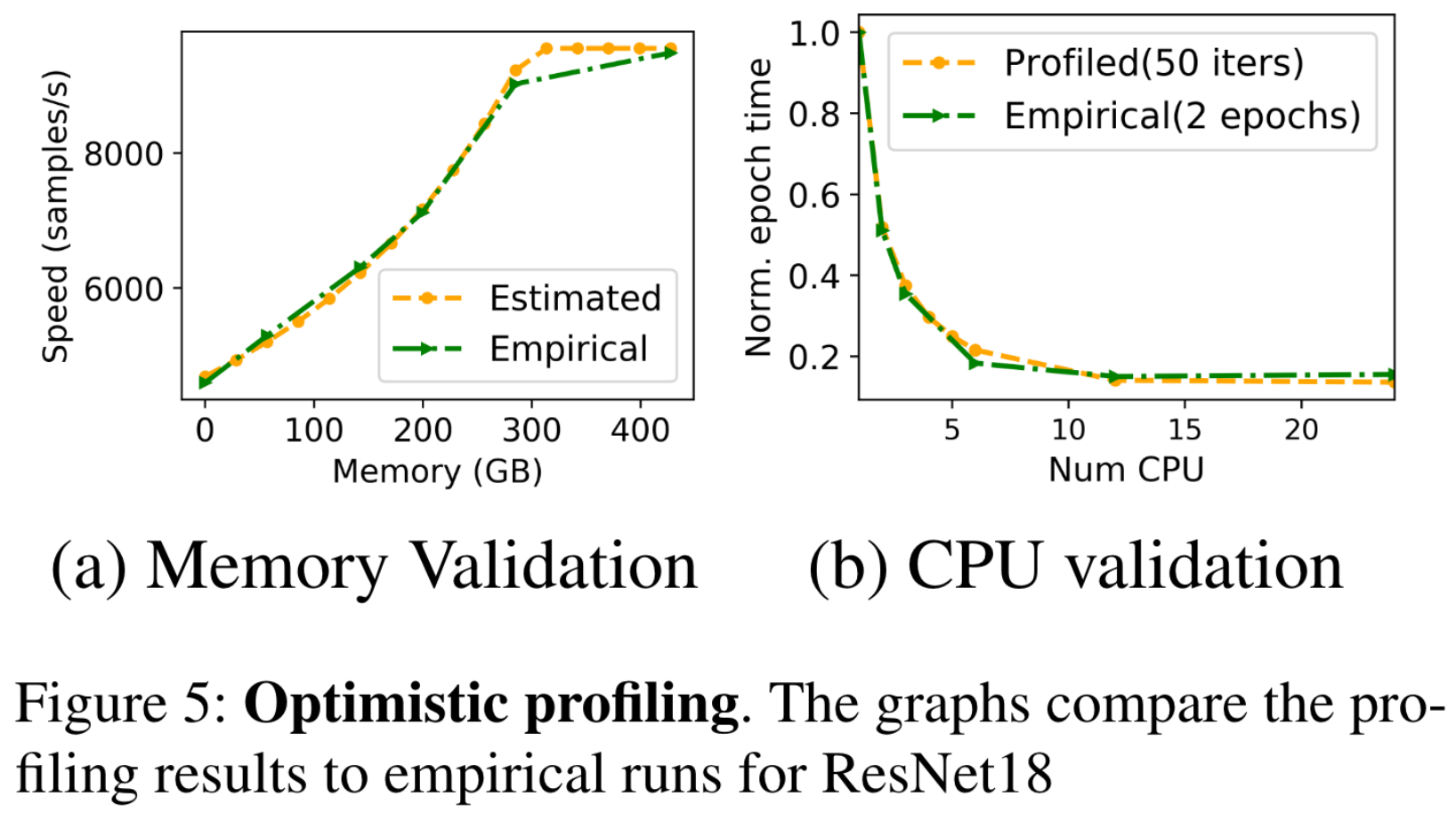
Exact throughput values for a job with varying CPU allocations is not necessary. A curve depicting the empirical job throughput is enough to identify the best-case CPU allocation for a job.
We start with the maximum CPU allocation and do a binary search on the CPU values to estimate job throughput.
- If the profiled point resulted in a throughput improvement that is less than a fixed threshold (say 10%), then we continue binary search on the lower half of CPU values,
- else we profile more points on the upper half.
Scheduling mechanism
To pack the jobs onto servers, we first construct a job demand vector that indicates the GPU demand, and best-case CPU and memory requirements for the job. We identify the best-case values using the resource sensitivity matrix. We pick the minimum value of CPU and memory that saturates the job throughput.
Multi-dimensional bin packing problem is NP hard
Synergy-GREEDY
A naive greedy multi-resource packing algorithm translates to a first-fit approximation of the multi-dimensional bin packing problem.
- It can result in auxiliary resources being exhausted by jobs, while leaving GPUs underutilized, and fragmented.
- It also hurts the fairness of the scheduling policy as some jobs can be skipped over for a long time if their resource requirements are not met.
Synergy-OPT
Case 1: All the resources on a single machine
Maximize
where
Subject to:
where
Case 2: Resources are spread across machines
The objective here is to minimize the number of jobs that get fragmented to account for the communication overhead when jobs are split across machines.
Introduce a new variable
- Solving two LPs per scheduling round is computationally expensive. As cluster size and the number of jobs per round increases, the time to find an optimal allocation increases exponentially
- The allocation matrix obtained with the second LP can result in fractional GPU allocations when jobs are split across servers; for instance, a valid allocation might assign 3.3 GPUs on server 1 and 2.7 GPUs on server 2 for a 6 GPU job. Realizing such an allocation requires a heuristic rounding off strategy to ensure non-fractional GPU allocations, as GPU time or space sharing, and its impact on job performance is considered beyond the scope of this work.
Synergy-TUNE
Objective:
- We do not affect the fairness properties of the scheduling policy used
- The expensive GPU resources are not underutilized
Allocation Requirements:
- The GPU, CPU, and memory resources requested by a single-GPU job must all be allocated on the same server.
- A multi-GPU distributed-training job can either be consolidated on one machine, or split across multiple machines.
The CPU and memory allocations must be proportional to GPU allocations across servers. synchronize
We need to ensure that no job runs at a throughput lower than what it would have achieved if we allocated a GPU-proportional share of CPU and memory resources.
Respect the priority order of jobs identified by the scheduling policy.
Only ONE RULE:
Synergy-TUNE the total requiremtn of GPU in a set of runnable jobs for a round as the top
Next, Synergy-TUNE greedily packs each of these runnable jobs along multiple resource dimensions on one of the available servers, with the objective of minimizing fragmentation.
However, it is possible that the job cannot fit in the cluster along all dimensions. In such a case,
-
We check if the job’s demand vector is greater than proportional share of resources, In this case, we switch the job’s demand to GPU-proportional share and retry.
-
If the job still does not fit the cluster, or if the job’s demand vector was less than or equal to GPU proportional allocation in step (1), then, we do the following.
- We repeat step (1) ignoring the job’s CPU and memory requirements. We find a server that can just satisfy the job’s GPU requirements. We know by construction that there is at least one job on this server, which is allocated more than GPU-proportional share of resources. We identify the job or a set of jobs (Js) on this server by switching whom to GPU-proportional share, we can release just as much resources required by the current job j. We switch the jobs in Js to fair-share and by design, job j will fit this server.
- We continue this recursively for all runnable jobs.